Keep-Alive Wasn’t Enough: Why HTTP/2 Introduced Multiplexing
During my undergrad, I remember hearing these terms, and my first understanding was that they all just meant one thing: persistent connections. But boy, did I generalize. HTTP versions looked so difficult to understand at the time.
"It's just enabling client-server communication over the web, what could be so complex about this?" - I thought to myself.
But today, let’s clear up the confusion that a lot of folks have around HTTP versions, especially the shift from HTTP 1.1 to HTTP 2. While both use persistent connections, the real game changer in HTTP/2 was multiplexing, which took connection reuse to a whole new level.
HTTP 1.1
Well, this was a big step up from HTTP 1.0 — although nowhere close to as revolutionary as HTTP 2.0. But hey, it was a big deal back in the day (I probably wasn’t even born then, but anyways :p).
In HTTP 1.0, a new connection had to be opened and created every single time a request was made. So let’s say you had a cool website powered by HTML and CSS, with multiple HTML pages and a few CSS files. To fetch each of these, a new request would be needed and for every request, a new connection had to be initiated. Once the response was received, the connection would be closed.
Now, this obviously wasn’t optimal because creating a new connection every single time is not cheap. Every time a request is made, the client and server need to perform a TCP handshake. If the site is using HTTPS (which most do), there’s also a TLS handshake on to made on top, adding even more overhead. All of this takes time and resources, on the client’s end and the server’s. So, for websites with multiple assets like images, CSS files, JavaScript, and fonts, the repeated connection setup for each of those requests becomes very inefficient and slow.
Then came our hero: HTTP 1.1. What made it special was that it introduced support for Keep-Alive. Persistent connections were now the default. That means, after the first response, the same TCP connection could be kept alive and reused for additional requests. So you could now fetch all the resources the client needs (HTML, CSS, JS, etc.) using the same connection.
Interesting, innit?
Then Why HTTP 2.0?
Now comes the twist.
Yes, you could send multiple requests using a single connection in HTTP 1.1 , but it still suffered from an issue called Head-of-Line Blocking (HOL blocking).
Don’t fret, lemme explain.
In HTTP 1.1 (without pipelining), requests are typically sent one after the other — meaning the second request is only sent after the response to the first request is received. So even though the connection is kept alive, the requests are still handled sequentially. This becomes a bottleneck when one of the requests (say Request 1) is slow to respond.
Now imagine: Request 1 is taking its own sweet time, maybe it's blocked on the server or just slow to process. Until that response comes back, Request 2 can’t even be sent, let alone processed. So the entire flow gets stuck waiting on one slow response.
That’s Head-of-Line blocking in HTTP 1.1 ...and yeah, it’s kinda frustrating.
Pipelining to the Rescue? (Well, sorta)
HTTP 1.1 tried to address this (partially) through something called pipelining.
Pipelining wasn’t widely used, though, because HOL blocking issues still persisted. What it did was allow multiple requests to be sent without waiting for responses but the responses still had to arrive in the same order as the requests.
That meant, yes, you could fire off requests in any order, but you'd still be stuck waiting for earlier responses to come through first.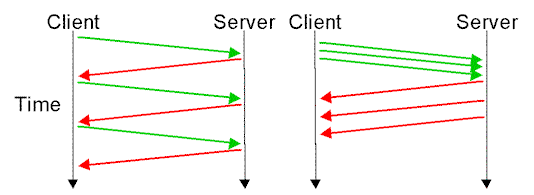
HTTP 2.0: The Modern Day Legend
HTTP 2.0 was a game-changer. It introduced Multiplexing , which was layered on top of Keep-Alive.
What that means is: multiple requests can now be sent simultaneously and responses can arrive in any order. This eliminated Head-of-Line blocking at the application layer.
HTTP 2.0 also introduced other improvements like a header compression algorithm called HPACK and other cool things; we’ll delve into those in upcoming blogs.
But Wait… HOL Still Exists?
Yep. What HTTP 2.0 didn’t fix was Head-of-Line Blocking at the transport layer.
“Transport layer?” I hear you ask.
Well, we all know (and have probably memorized) that TCP is stateful and UDP is stateless. TCP is connection-oriented and it ensures reliable and ordered delivery of data packets. UDP is its lazy (yet fast) cousin and it just sends and forgets xD.
Now here’s where things get interesting:
TCP ensures every packet arrives by retransmitting lost packets. But it also ensures that packets are delivered in order. So let’s say three packets are sent, and the second one is lost. TCP will keep retrying and retransmitting that lost packet until it’s acknowledged. Until then, packet 3 and the rest are blocked — even if they arrived safely. This is transport-layer HOL blocking, and it can slow down transmission significantly.
So What’s Next?
Enter: HTTP 3.0, which is built on QUIC, not TCP.
It’s not as widely used yet, but it’s definitely the future. To eliminate transport-layer HOL blocking, HTTP 3 uses UDP, which allows independent delivery of streams without blocking others.
We’ll explore HTTP 3 and QUIC in the next blog, so stay tuned ;)
Thanks for reading - and do reach out if you’ve got any doubts or feedback. Happy learning!
